日本語テキストを音声に変換するには?
これまでハードウェアのプログラムと言えばアセンブリ言語やC言語が中心でした。少ないリソースを有効に活用するには、コンピュータに近い感覚のコーディングが必要だったためです。この状況はラズパイの登場で大きく変わり、Pythonなどの高水準言語でも制御プログラムを書けるようになりました。
そこで本記事からは、Pythonなどの話題のプログラミング言語を使って、ハードウェアの力を最大限に引き出す実践的なコーディング手法を学習していきます。
第1回目のテーマは「ラズパイで日本語テキストを読み上げる」です。
記事の中では発話するアプリケーションの作成を通して、必要なシステム構成やPythonのコーディング手法、シェルスクリプトなど、ほかのアプリケーションとの連携方法を紹介します。

目次
- 本記事の目的と想定している読者層
- ラズパイで日本語テキストを読み上げる
- 必要な機器
- Pythonで音声合成(Text-to-Speech)するには?
- 音声ファイルの作成方法の違いによるシステムの分類
- 5.1. 音声ファイルを作成する3つの方法とは
- 5.2. 方法A あらかじめ録音
- 5.3. 方法B サーバで作成
- 5.4. 方法C オフラインで作成
- 5.5. どの方法を選択すれば良いか?
- まとめ
1. 本記事の目的と想定している読者層
アセンブリ言語やC言語が中心だったハードウェアの開発環境はArduinoとラズパイの登場で大きく変わりました。ArduinoはC++で、ラズパイは普段から慣れ親しんだPythonで制御できます。
近年ではPythonを使ってマイコンボードを制御するプログラムを作りたいという要望が高くなり、MicroPythonやCircuitPythonなどPythonをベースとしたプログラミング言語が登場しています。
しかしながらMicroPythonなどのPythonから派生した言語は、Pythonの持つ標準ライブラリを一部サポートしていないなど、機能が制限されています。
これはPythonが動作するためには高速な処理速度や多くのメモリが必要であり、マイコンボードという制限された環境ではパソコンと同等のPythonが動作しないということが原因です。
ラズパイはマイコンボード程度のサイズでありながら高い処理能力を持っています。OSにはLinuxを採用しその実力はパソコンと変わりません。Pythonもパソコンと同じものが動作します。パソコンと同等のPythonが動作し、手軽に入手できるマイコンボードはラズパイだけです。
また、これはラズパイの能力を引き出すために「Pythonのコーディング力」が欠かせないことを意味します。
そこで本記事ではPythonを使ってシステムを構築できるように、実践的なコーディング手法を解説していきたいと思います。
対象とする読者は「とりあえずPythonを使ったことがある」方を想定します。記事の中ではPythonの文法なども補足するので「変数や関数、if文とは何か?」といった基本的な点が押さえられていれば問題ありません。
2. ラズパイで日本語テキストを読み上げる
第1回目のテーマは「ラズパイで日本語テキストを読み上げる」です。
「テキストを読み上げる技術」を近年では「Text-to-Speech(TTS)」と呼ぶようになりました。「音声合成」という呼び方の方が馴染みのある方が多いかも知れません。
本記事ではラズパイにスピーカーを接続して音声合成(Text-to-Speech)技術を使った日本語で声を発する(発話する)システムを構築します。
一口に「発話」と言ってもその方法はいくつか考えられます。連載ではPythonで発話する際に考えられるシステム構成を3つ挙げ、それぞれを構築する方法を4回(パート1〜パート4)に分けて解説していきます。
パート1(今回)はシステム構成とシステム化のポイントを解説、パート2からパート4は3つのシステム構成を具体的なアプリケーションの形にします。
本記事は特に「Pythonのコーディング力」にポイントを置くのでアプリケーションはシンプルな構成を目指します。また、ラズパイのOSのベースとなるLinuxでプログラムが動作する仕組みなど、ラズパイ上で現実的なアプリケーションを構築する手法なども合わせて解説していきます。
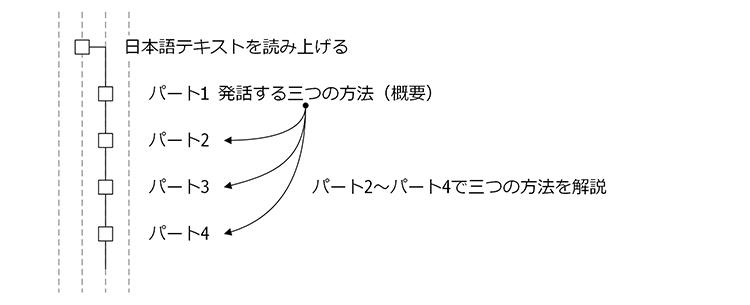
本記事の構成
3. 必要な機器
本記事で紹介するアプリケーションの動作を検証したラズパイの構成は以下の通りです。
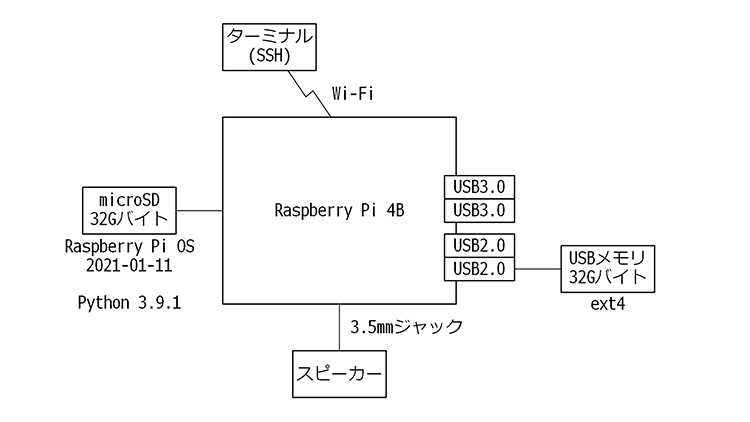
システム構成(ブロック)
| 項目 | 仕様 |
| ラズパイ | Raspberry Pi 4B |
| microSD | 32Gバイト |
| OS | Raspberry Pi OS 2021-01-11Raspbian GNU/Linux 10 (buster) |
| Python | 3.9.1 |
| Wi-Fi | 固定IPアドレス(192.168.11.51) |
| スピーカー | 3.5mmジャック |
| USBメモリ | 32Gバイト ext4 |
ラズパイの操作はSSH接続したターミナルで行います。
使用したラズパイには記憶領域を増やすために32GバイトのUSBメモリを使用していますが、紹介するアプリケーションはそれほど大きなものではないので、USBメモリはなくても問題ありません。
本記事ではハードウェアの構成を次のように記載する場合もあります。

システム構成(ツリー)
上の2枚の図「システム構成(ブロック)」と「システム構成(ツリー)」はどちらも同じ構成を表現しています。本記事では状況に応じて構成を上記のいずれかの形で表現します。
4. Pythonで音声合成(Text-to-Speech)するには?
まず、Pythonは一旦置いといて、プログラムを使ってラズパイなどの電子機器に発話させるシステムの構成から考えてみましょう
プログラム全体の構成は概ね次のようになります。
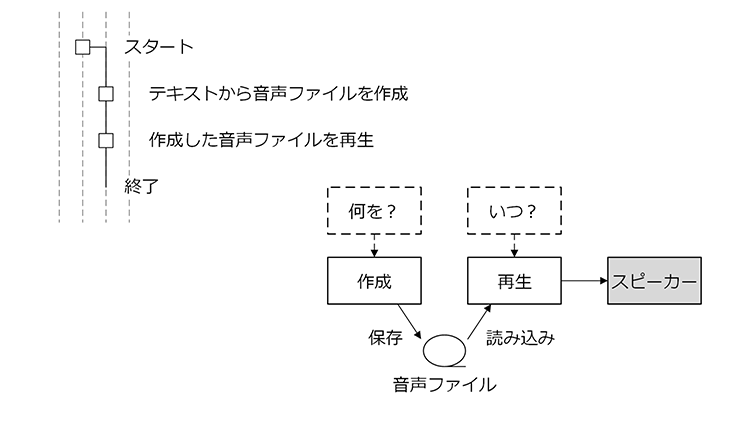
電子機器に発話させるプログラム
全体的な流れとしては
- テキストから音声ファイルを作成
- 作成した音声ファイルをベースに「何を発話させるか?」「発話のタイミングは?」
などの処理をプログラムに行わせることになります。
本記事では発話するプログラムの2つの主要なパートである「音声ファイルの作成」と「音声ファイルの再生」を中心に説明します。
音声ファイルの作成方法については、大別すると3種類の方法があります。アプリケーションの目的によってどの方法を選択すべきかが変わるため、万能の方法というものはありません。
一方の音声ファイルの再生にも選択肢はいくつかありますが、どの方法を選択してもアプリケーションの目的には大きく影響しません。
本記事では以降、「音声ファイルの作成方法の違い」に注目してシステム化を考えます。
本記事で作成するアプリケーションは「mp3」「wav」のいずれかの形式を使用します。それぞれ、mp3はデータサイズを小さくできる特徴を持ち、wavは編集しやすい特徴を持つ音声フォーマットです。
5. 音声ファイルの作成方法の違いによるシステムの分類
音声ファイルの作成には大きく分けて3つの方法があります。発話するシステムは、この音声ファイルの作成方法によって特徴が変わります。
5.1. 音声ファイルを作成する3つの方法とは
発話するシステムは特に音声ファイルの作成方法によって特徴が変わるので、システム設計の際には十分に考慮する必要があります。
音声ファイルの作成方法は大別すると
A. あらかじめ録音しておく
B. 読み上げるテキストをサーバに送り作成
C. オフラインで作成
の3つの方法があり、それぞれ一長一短があります。
それぞれの方法について「人間に近い自然な発話」「セットアップの手軽さ」「状況に合わせたメッセージ」の観点から利点・欠点を考えると以下のように大別できます。
| 音声ファイルの作成方法 | 利点 | 欠点 |
| あらかじめ録音 | 最も人間に近い発話 | 録音したメッセージしか再生できない |
| サーバで作成 | ややぎこちないが状況に応じた発話 | 常にインターネット接続が必要 |
| オフラインで作成 | ラズパイだけで状況に応じた発話ができる | インストールが大変で発話がぎこちない |
5.2. 方法A あらかじめ録音
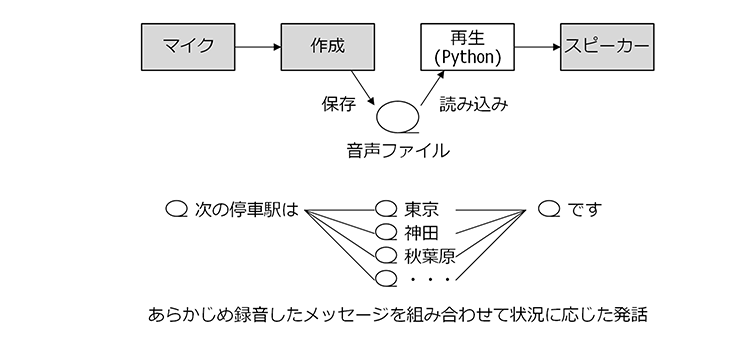
音声ファイルを「あらかじめ録音」する方法は以下のような構成となります。
音声ファイルをあらかじめ録音
この方法の利点は
- 人間に近い発話ができる
点です。
一方、欠点は
- 録音したメッセージしか再生できない(固定メッセージ)
- 音声ファイルを格納するために記憶領域が必要
などです。
ただし「固定メッセージ」といっても
「次の停車駅は」「東京/神田/秋葉原/・・・」「です」
のように文節や単語単位で録音しておき、実行時に音声ファイルを組み合わせて状況に合ったメッセージを作成する方法にも対応できるため、利用シーンによっては実用的な選択肢です。
パート2ではあらかじめ録音する方法の例として「タイマーを使って特定の時間に発話するアラームアプリケーション」を作成します。
5.3. 方法B サーバで作成
音声ファイルを「サーバで作成」する方法は以下のような構成となります。
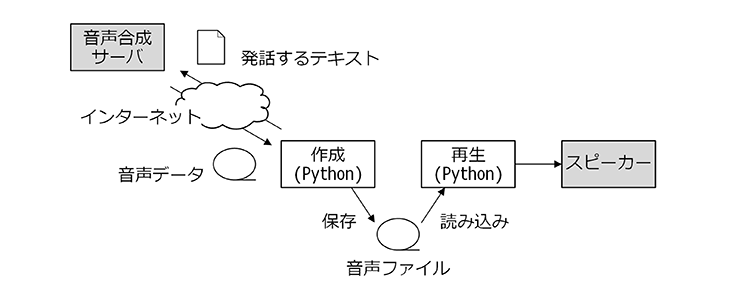
音声ファイルをサーバで作成
読み上げるテキストを音声合成(Text-to-Speech、TTS)サーバに送り結果の音声データを受信、音声ファイルとして保存する流れになります。
この方法の利点は
- ややぎこちないが状況に応じて自由なメッセージを発話できる
点です。
一方、欠点は
- 常にインターネット接続が必要となる
- ネットワークの信頼性がシステムに影響する
- ネットワークに接続できない場合のバックアップが必要となる
- 音声合成サーバの使用が有料の場合がある
などです。
音声ファイルをサーバで作成する方法は、ネットワークの利点・欠点が、そのままシステムの利点・欠点にも直結します。
「読み上げるテキストを音声合成サーバに送る」「結果の音声データを受け取る」動作はインターネットを介して行います。この通信にはWeb APIの一種であるRESTと呼ばれる仕組みを利用します。
パート3では、このRESTと呼ばれる技術を使用して音声合成サーバと通信し音声ファイルを作成する方法を紹介します。使用する音声合成サーバはGoogle gTTSです。
5.4. 方法C オフラインで作成
音声ファイルを「オフラインで作成」する方法は以下のような構成となります。
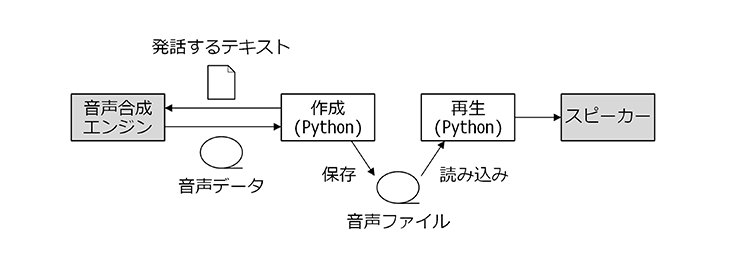
音声ファイルをオフラインで作成
構成は「方法B サーバで作成」のサーバ部分が音声合成エンジンに変わります。
この方法の利点は
- ラズパイだけで状況に応じた発話ができる点です。
一方、欠点は
- インストールが大変
- 発話がぎこちない
などです。
音声ファイルをオフラインで作成するには音声合成エンジンのほかに辞書や音響モデルなどのファイルが必要です。
パート4では日本語に対応した音声合成エンジンの一つであるOpen JTalkを使用して音声ファイルを作成する方法を紹介します。
5.5. どの方法を選択すれば良いか?
3つの音声ファイルの作成方法から最良の方法を選択するポイントは「メッセージの再生が固定されているか?」です。
固定メッセージと言っても
a. 発話するメッセージの大部分は変化しない
b. メッセージが変化する部分は地名などの一部のみ
c. 変化する部分もパターンが決まっている
これらに合致する場合であれば、方法Aのあらかじめ録音方式でも問題ありません。
次にポイントとなるのは「常にネットワークに接続できるか?」です。
ネットワークを使ったシステムを構築する場合には、システム構築に合わせてネットワーク信頼性の確保や、接続できない場合の予備ネットワークなども考慮しなくてはいけません。
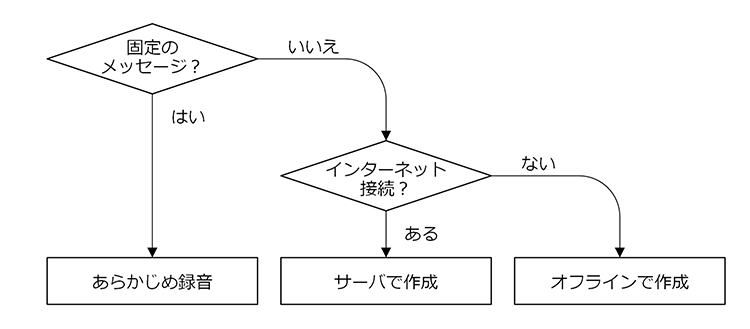
音声ファイルを作成する方法を選択
6. まとめ
Pythonで発話するアプリケーションを設計する場合、プログラムは「音声ファイルの作成」と「音声ファイルの再生」の2つのパートが中心となります。
中でも音声ファイルの作成は、方法によってアプリケーションの特徴も決まるので、設計の際は入念に検討する必要があります。
音声ファイルの作成方法を大別すると「あらかじめ録音」「サーバで作成」「オフラインで作成」の3つです。
パート2ではあらかじめ録音について、パート3・パート4ではそれぞれサーバで作成・オフラインで作成について、Pythonのプログラムを作成しながら解説します。
今回の連載の流れ
(1)日本語テキストを音声に変換するには?(今回)
(2)あらかじめmp3に録音した音声を再生する
(3)REST(Web API)を使って発話する
(4)OpenJTalkを使ってオフラインで音声合成


