あらかじめmp3に録音した音声を再生する
「ラズパイで日本語テキストを読み上げる」のパート2では、あらかじめ録音した音声を再生する方法を説明します。
音声ファイルはあらかじめパソコンの録音機能などを使って作成しておいてください。記事では音声ファイルを再生する方法としてPythonのライブラリとコマンドを使った2つの方法を紹介します。
また、コマンドを使った再生方法にタイマーを組み込み「アラーム」アプリケーションを作成します。
この記事では、決まった時間にあらかじめ録音した音声ファイルを再生する「アラーム」アプリケーションを作りながら、実際の業務でよく使われる「Pythonでの時間の取り扱い方法」についても学習を進め、ゼロからPythonのプログラムを作成する方法についても解説していきます。

目次
- あらかじめ録音した音声ファイルを再生する
- 音声ファイルの再生にPythonライブラリ「pydub」を使用
- 2.1. 本プログラムの構成
- 2.2. PEP8に準拠したコーディング
- 2.3. 準備
- 2.4. Pythonプログラム p1.py
- 2.5. プログラムの説明
- 2.6. プログラムの実行と検証
- 音声ファイルの再生にコマンド「ffplay」を使用
- 3.1. 本プログラムの構成
- 3.2. 準備
- 3.3. Pythonプログラム p2.py
- 3.4. プログラムの説明
- 3.5. プログラムの実行と検証
- タイマーを使った「アラーム」アプリケーションの作成
- 4.1. 本プログラムの構成
- 4.2. 準備(タイマーを追加できるようにp2.pyを改修)
- 4.3. Pythonプログラム p3.py
- 4.4. プログラムの説明
- 4.5. プログラムの実行と検証
- まとめ
1. あらかじめ録音した音声ファイルを再生する
「ラズパイで日本語テキストを読み上げる」シリーズのパート2ではあらかじめ録音された音声ファイルを再生する方法を紹介します。
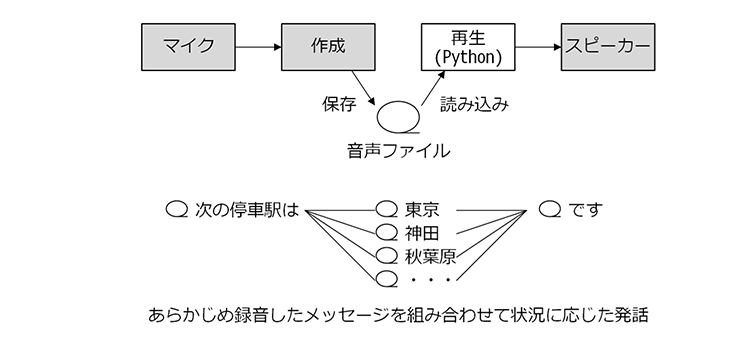
音声ファイルをあらかじめ録音
今回紹介するあらかじめ録音された音声ファイルを再生する方法は「発話と言えるのか?」と思うかも知れません。
この方法は最も自然に発話できる方法であり、電車やバスを始めとした公共交通機関などに採用されており、正確に内容を把握する必要があるシーンでは欠かせない技術です。
また「あらかじめ録音しておく」と言っても単に同じメッセージを繰り返すだけではなく
「次の停車駅は」「東京/神田/秋葉原/・・・」「です」
のように、文節や単語単位で音声ファイルを作成しておき、実行時に組み合わせてメッセージを作成する使い方ができるので、さまざまなシーンで応用できます。
本記事ではあらかじめ録音された音声ファイルを再生する方法として
A.Pythonのライブラリpydubを使用する
B. Linuxのコマンドを使用する
の2つを紹介します。
「A.」のpydubというPythonのライブラリを使用する方法は、セットアップが必要ですがPythonのプログラムと親和性が高い方法です。
「B.」のLinux(Raspberry Pi OSのベース)のコマンドを使用して再生する方法は、OSにインストールされているコマンドをPythonで呼び出す方法です。
Pydubを使用する場合もライブラリの内部ではLinuxのコマンドを呼び出しています。「A.」と「B.」の違いは、pydubには必要な部分を切り出すための音声ファイル編集機能がある点です。
今回の例は、音声ファイルの再生のみ行うためpydubの選択は必須ではありません。
本記事では
- pydubで音声ファイルを再生するPythonプログラムの作成(p1.py)
- Linuxのコマンドで音声ファイルを再生するPythonプログラムの作成(p2.py)
- p2.pyにタイマー機能を追加して「アラーム」アプリケーションを作成(p3.py)
の流れで解説します。
2. 音声ファイルの再生にPythonライブラリ「pydub」を使用
最初にPythonのライブラリpydubを使用した音声ファイルの再生方法を紹介します。
2.1. 本プログラムの構成
以下がpydubライブラリを使用して音声ファイルを再生するアプリケーションの構成です。
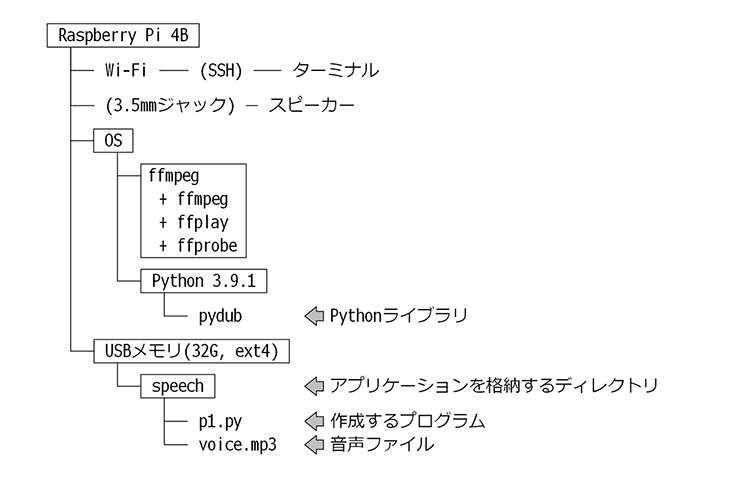
システム構成
このプログラムは「p1.py」の起動後、pydubで音声ファイルを再生するシンプルな構成になっています。
ディレクトリ「speech」を作成して、その中にp1.pyと音声ファイル「voice.mp3」を格納してください。
筆者の環境では、記憶領域を増やすためUSBメモリを使用しています。今回のアプリケーションはそれほど大きなものではないのでUSBメモリを使用しなくても問題ありません。大量の音声ファイルを制御するなど、USBメモリを使用する場合はspeechディレクトリをホームディレクトリ(/home/pi)内にデータを保管します。
p1.pyはスケルトン(ソースコードの雛形)として新たなプログラムを書き始める時のベースとして使用できるので後ほど詳細に内部を説明します。
ソースコードの記述はPEP8に従います。
2.2. PEP8に準拠したコーディング
ソースコードの記述には「PEP8」と呼ばれるコーディング規約を採用します。日本語訳されたものはこちらです。
PEP8とはPythonでプログラムを書く際に必要な「どのように記述するべきか」の基準を定義した文書であり、関数・変数の名付け方や括弧・スペースの置き方などが詳細に記載されています。
Pythonに限らずプログラミング言語には「こう書かなければ動かない」という文法があり、コーディングの際は必ず文法に従わなければなりません。
一方で関数名・変数名の名付け方や括弧・スペースの置き方などは文法が許す限りプログラマの自由に書くことができます。ただし自由だからと言って好き勝手に記述してしまうとさまざまな問題が起こります。
業務で作成するプログラムは資産です。単に動けばいいというものではなく、長期的にメンテナンスする必要があり、また一部を改修してほかのアプリケーションのベースとなります。当然、作った本人がメンテナンスや改修にあたるとは限りません。
プログラマが自由にコーディングを進めてしまったプログラムは、あとから手を入れるのが非常に大変な作業となってしまうので記述に一定のルールを持たせることが必要です。
これを「コーディング規約」と呼びPEP8もその一つです。ただしPEP8は「遵守しなければならない」というものではありません。大切なのはソースコードを通して一貫したルールに則っていることです。もし所属する組織にコーディング規約がある場合はそれに従い、定義されていない部分をPEP8で補うといった使用方法が良いでしょう。
2.3. 準備
pydubを使用する前にライブラリをインストールします。
ターミナルを起動して以下のコマンドを入力してください。
pip install pydub
pydubは内部でffmpegが提供するコマンドを使用します。Raspberry Pi OSにはあらかじめインストールされているか確認するため、以下のコマンドでインストール済みか確認します。
which ffmpeg
ターミナル上に「/usr/bin/ffmpeg」などと行が表示されれば問題ありません。何も表示されない場合はffmpegがインストールされていないので、以下のコマンドでインストールします。
sudo apt install ffmpeg
2.4. Pythonプログラム p1.py
Pythonのプログラムを作成します。
nanoなどのテキストエディタを起動して以下の通り入力します。ファイルはp1.pyの名前で保存してください。
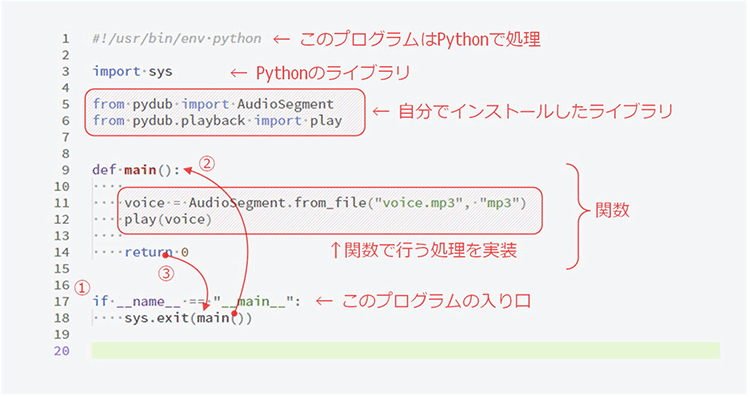
#!/usr/bin/env python
import sys
from pydub import AudioSegment
from pydub.playback import play
def main():
voice = AudioSegment.from_file("voice.mp3", "mp3")
play(voice)
return 0
if __name__ == "__main__":
sys.exit(main())
2.5. プログラムの説明
p1.pyはスケルトン(ソースコードの雛形)としても使用できます。音声ファイルの再生に必要な部分を編みかけするとプログラムの構造は以下のようになります。
p1.pyを雛形として使う
これがゼロからPythonのプログラムを書き始める際にスタートとなるソースコードです。
1行目は「shebang(シバン)」と呼ばれる記述で「このプログラムを処理するインタプリタ(今回はPython)」を指定します。
#! の後ろがインタプリタ名(パス)です。
Windowsはファイルの拡張子で関連するアプリケーション(インタプリタ)を特定しますが、ラズパイのOSの元となるLinuxではスクリプト(プログラム)の1行目にインタプリタ名を指定することになっています。
これによってターミナルからは次のようにプログラムの「パス+ファイル名」だけで起動することができます。(「./」は「現在のディレクトリ」を示すパス表記です)
./p1.py
もし1行目にインタプリタが指定されていない場合、上記のようには呼び出すことができません。インタプリタが指定されていない場合は以下のように入力することで起動できます。
/usr/bin/env python xx.py
3行目はimport文と呼ばれるコマンドです。ここではPythonの標準ライブラリ「sys」を読み込んでいます。これによってsysライブラリで定義されている機能を使えるようになります。
本プログラムではexit()関数を使うためsysライブラリの読み込みが必要です。
5、6行目はインストールしたpydubの機能を使用するためのimport文です。
3行目のimport文は「sysライブラリ内の全ての機能を使用できるようにする」という意味です。
一方、5行目は「pydubライブラリ内のAudioSegmentを使用できるようにする」、また6行目は「pydubライブラリ内のplaybackモジュールにあるplayを使用できるようにする」という意味です。from,importを使うことでライブラリ内の一部の機能を読み込むことができます。
9〜14行目が関数「main()」です。
ここでは
- pydubに音声ファイルの名前(パス)を伝えてオープンする
- p「1.」でオープンした音声ファイルを再生する
- p関数を終了する(呼び出し元に終了ステータス0を返す)
と処理が進みます。
17行目はこのプログラムの入り口です。
Pythonインタプリタはソースコードの上にある行から実行していきますが、6行目までのimport文は「読み込むだけ」で具体的な処理を行いません。またmain()関数は「『main()関数を実行する』という明示的な呼び出し」がなければ実行されません。結果、17行目のif文がこのプログラムの最初の処理となります。
if文の条件であるname == “main”は、このソースコードが
A. 実行されるために呼び出されたのか?
B. import文で呼び出されたのか?
を判別するための記述です。
このソースコードがimport文で呼び出された場合は、あくまでも「準備段階」なので具体的な処理をしません。実行されるために呼び出された場合、if文は真となりmain()関数を呼び出します。
この部分は
- 「実行されるために呼び出されたのか?」の判定(①)
- main()関数の呼び出し(②)
- main()関数の終了(③)。main()関数から0が渡される
- 「3.」で受け取った0を引数にしてsys.exit()関数を呼び出し(ここでプログラムは終了)
となります。
網掛け部分は、仕様で定めた「pydubを使って音声ファイルを再生する」ために必要な記述です。ゼロからPythonのプログラムを作成する際は、網掛け部分を書き換えれば良いことになります。
2.6. プログラムの実行と検証
作成したアプリケーションの実行にはターミナルを使用します。
ターミナルを起動してcdコマンドでspeechディレクトリの中に移動してください。speechディレクトリの中にはPythonプログラム「p1.py」と音声ファイル「voice.mp3」があるはずです。
以下のコマンドを入力してください。アプリケーションが実行されます。
./p1.py
スピーカーから音声ファイル「voice.mp3」の内容が再生されれば成功です。
再生中はターミナル上に以下のような「音声ファイルの情報を示すインジケータ」が表示されます。
Input #0, wav, from '/var/folders/zc/gmm566813xjcy6n63nz1zhlh0000gn/T/tmpbnj_bz0b.wav':
Duration: 00:00:09.02, bitrate: 384 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 24000 Hz, 1 channels, s16, 384 kb/s
8.92 M-A: 0.000 fd= 0 aq= 0KB vq= 0KB sq= 0B f=0/0
これはplay()関数の呼び出しで表示されます。
残念ながら、これを非表示にする方法はplay()関数には実装されていません。そこで次のPythonプログラムでは、play()関数の中で使用しているffplayコマンドを直接呼び出すことで、このインジケータを非表示にします。
3. 音声ファイルの再生にコマンド「ffplay」を使用
Pythonのライブラリ「pydub」を使用せずに直接コマンド「ffplay」を呼び出すシンプルな音声ファイルの再生方法を紹介します。
3.1. 本プログラムの構成
以下がffplayコマンドを使用して音声ファイルを再生するアプリケーションの構成です。
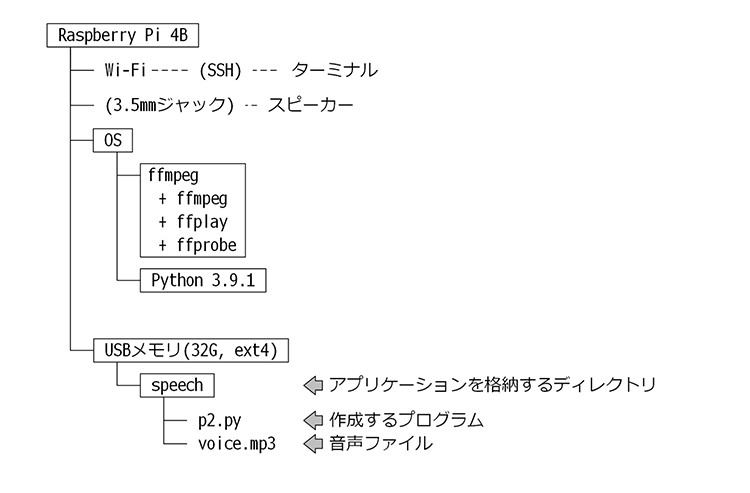
システム構成
「pydubライブラリを使った音声ファイルの再生」では実行中にターミナル上にインジケータが表示されてしまいます。これを非表示にするためにはpydubが内部で再生に使用するffplayコマンドを直接呼び出します。
また、pydubの持つ音声ファイルの編集機能を使う予定がない場合も直接ffplayコマンドを呼び出した方がシンプルです。
以下が前回のプログラム「p1.py」の処理とデータの流れです。
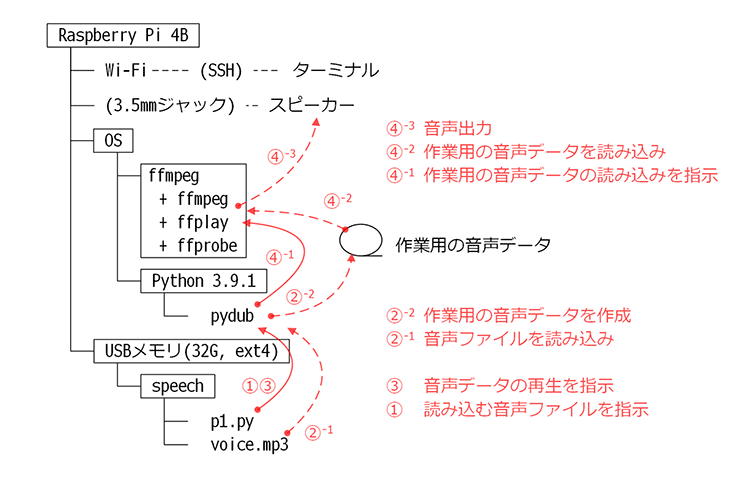
pydubを使った音声ファイルの再生
pydubを使う場合の処理の流れは
- p1.pyからpydubの関数を呼び出して音声ファイルを指定
- pydubが音声ファイルを読み込み作業用の音声データを作成
- p1.pyからpydubの関数を呼び出して作業用の音声データの再生を指示
- pydubがffplayを呼び出して作業用の音声データの再生を指示
というように一旦、作業用の音声データが作成されます。
これはpydubが音声データの加工含む構成なので今回のように音声ファイルの再生のみの用途では不要な工程です。
以下がpydubライブラリを使用せず、ffplayコマンドを直接呼び出す際の処理とデータの流れです。
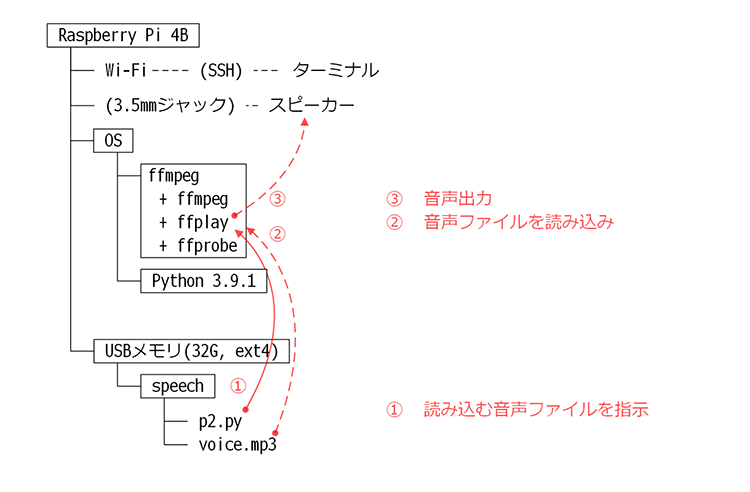
ffplayを直接呼び出す音声ファイルの再生
ffplayコマンドはRaspberry Pi OSにインストールされるコマンドなので、Pythonのプログラム内から直接呼び出せます。
3.2. 準備
ffplayはffmpegが提供するコマンドです。Raspberry Pi OSにはあらかじめインストールされているはずなので以下のコマンドで確認してください。
which ffplay
ターミナル上に「/usr/bin/ffplay」のような表示があれば問題ありません。ffplayがインストールされていない場合は何も表示されないので、前述したp1.pyの『準備』にあるようffmpegをインストールしてください。
3.3. Pythonプログラム p2.py
Pythonのプログラムを作成します。
nanoなどのテキストエディタを起動して以下の通り入力します。ファイルはp2.pyの名前で保存してください。
#!/usr/bin/env python
import sys
import subprocess
def main():
subprocess.call(["ffplay", "-nodisp", "-autoexit", "voice.mp3"],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL)
return 0
if __name__ == "__main__":
sys.exit(main())
3.4. プログラムの説明
Pythonプログラム「p1.py」で説明したスケルトンにffplayの呼び出しを加えただけのソースコードです。
本プログラムではffplayコマンドの呼び出しにsubprocess.call()関数を使用するので、Pythonの標準ライブラリ「subprocess」を読み込むimport文が必要な点に注意してください。
subprocess.call()関数はターミナルで次のようにコマンドを入力するのと同じように動作します。
ffplay -nodisp -autoexit -hide_banner voice.mp3
ffplayのオプションは次の通りです。
| オプション | 説明 |
| -nodisp | GUIのないコマンドライン(ターミナル)でffplayを使用する |
| -autoexit | 再生が終了したらffplayも終了する |
| -hide_banner | ターミナル上に詳細なメッセージを表示しない |
| voice.mp3 | 再生する音声ファイル |
音声ファイルがカレントディレクトリに存在しない場合は「/home/pi/speech/voice.mp3」のようにパスを含めます。
Pythonプログラム「p2.py」では-hide_bannerオプションを指定せず以下のようにffplayコマンドを呼び出しています。
ffplay -nodisp -autoexit voice.mp3
p2.pyではインジケータが表示されるのを防ぐためsubprocess.call()関数の引数に「stdout=subprocess.DEVNULL」と「stderr=subprocess.DEVNULL」を指定しています。そのため-hide_bannerオプションを指定しなくてもターミナル上には何も表示されません。
「stdout=subprocess.DEVNULL」と「stderr=subprocess.DEVNULL」の意味はパート4で解説します。
subprocess.call()関数の最初の引数にはターミナル上で入力するコマンドを指定します。ただしコマンドはスペース位置で区切って配列として引き渡す必要があります。
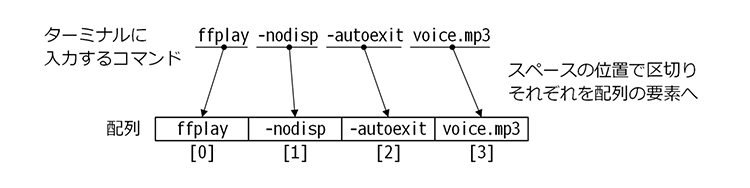
subprocess.call()関数に指定するコマンドは配列
3.5. プログラムの実行と検証
作成したアプリケーションの実行にはターミナルを使用します。
ターミナルを起動してcdコマンドでspeechディレクトリの中に移動してください。speechディレクトリの中にはPythonプログラム「p2.py」と音声ファイル「voice.mp3」があるはずです。
以下のコマンドを入力してください。アプリケーションが実行されます。
./p2.py
スピーカーから音声ファイル「voice.mp3」の内容が再生されれば成功です。
本記事では以降、音声ファイルを再生する仕組みにffplayコマンドを使った方法を使用します。
次はタイマーを使った「アラーム」アプリケーションへの応用例です。
4. タイマーを使った「アラーム」アプリケーションの作成
Pythonプログラム「p2.py」を改修して「アラーム」アプリケーションを作成します。
4.1. 本プログラムの構成
アラームの構成は以下の通りです。タイマー機能は全てPythonの標準ライブラリで作成できます。
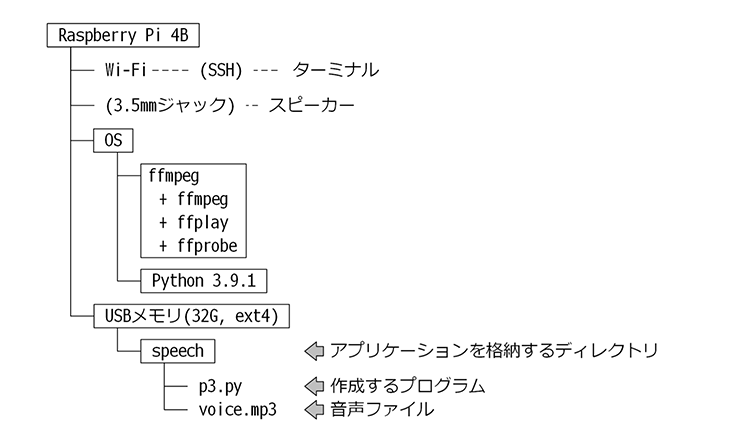
システム構成
アラームとは、あらかじめ決められた時間に起動して特定の処理を行うアプリケーションです。時間になるのを待っている間は、できるだけほかのアプリケーションの動作に影響を与えないように「おとなしく待機」しておくのが望ましい動作です。
そこでプログラムの処理フローは以下のようになります。

アラームの処理フロー
主処理はmain()関数です。main()関数が呼び出されると(プログラムがスタートすると)最初に「初回のアラーム時刻」と次のアラームまでの「アラーム間隔」を設定します。
その後プログラムは無限ループに入ります。本プログラムには無限ループを抜ける処理がありません。プログラムを終了するにはキーボードの「Ctrl+c」を押してください。
無限ループ内では常に「現在時刻はアラームの設定時刻を越えているか?」をチェックし、Trueの場合(アラームの設定時刻となった)は音声ファイルを再生します。
再生後は現在の「アラームの設定時刻」に「アラーム間隔」を足し「アラームの設定時刻」を更新します。
その後の「1秒間停止」は、if文にかかわらずループのたびに呼び出されプログラムの実行を1秒間停止します。
処理フローからも推察できるように、本プログラムはほとんどの時間「1秒間停止」していることになります。そのため本プログラムは長時間実行させても他のアプリケーションの動作に影響を与えません。
4.2. 準備(タイマーを追加できるようにp2.pyを改修)
それではPythonプログラム「p2.py」を修正して新たな処理を追加できるようにします。
以下が修正途中の状態です。
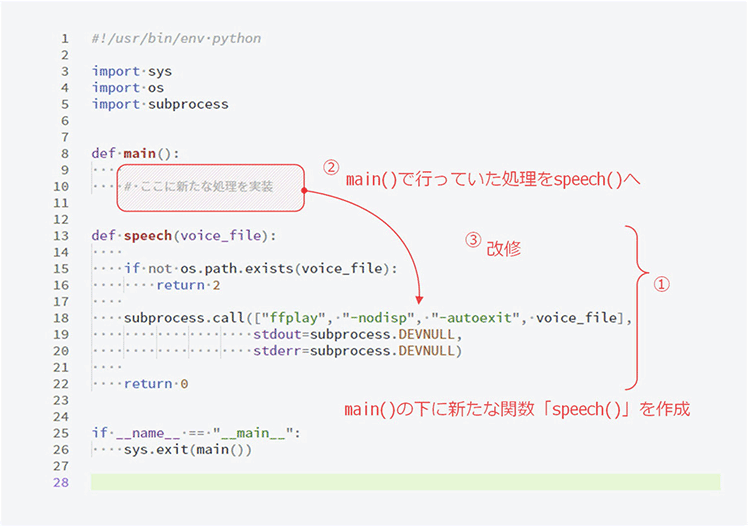
タイマーを追加できるようにp2.pyを改修
修正の手順は
- main()関数の下に新しい関数「speech()」を作成
- main()関数で行っていた処理をspeech()関数に移動
- ソースコードの改修
です。
ソースコードの改修はソースコード中で直接指定していた音声ファイル名を外部から受け取るようにします。具体的には
- speech()関数に引数「voice_file」を追加
- 引数「voice_file」の内容をチェックし存在しないファイルが指定されたらエラー
- subprocess.call()関数に渡すファイル名を引数「voice_file」に変更
の3点です。
ファイルの存在チェックを行うためにPythonの標準ライブラリ「os」を使用します。import文の追加を忘れないでください。
4.3. Pythonプログラム p3.py
以下が最終的なプログラムです。
#!/usr/bin/env python
import sys
import os
import subprocess
import datetime
import time
def main():
voice_file = "voice.mp3"
alarm = datetime.datetime( 2021, 2, 2, 18, 15, 0 )
offset = datetime.timedelta(minutes=1)
print("アラームは「{}から{}ごと」に設定されました".format(alarm, offset))
while True:
now = datetime.datetime.now()
if alarm <= now:
speech(voice_file)
alarm += offset
print("次のアラームは{}です".format(alarm))
time.sleep(1)
return 0
def speech(voice_file):
if not os.path.exists(voice_file):
return 2
subprocess.call(["ffplay", "-nodisp", "-autoexit", voice_file],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL)
return 0
if __name__ == "__main__":
sys.exit(main())
4.4. プログラムの説明
「初回のアラーム時刻」の設定はdatetime.datetime()関数を使用します。引数にはアラームを起動させたい日付時刻「2021年2月2日 18時15分0秒」(例)の数字部分を順に並べ「2021年2月2日 18時15分0秒」を指し示すdatetimeオブジェクトが変数「alerm」に格納されます。
「アラーム間隔」の設定はdatetime.timedelta()関数を使用します。
変数「offset」に格納されるのはtimedeltaオブジェクトです。timedeltaオブジェクトは2つの日付や時刻間の差を保持するオブジェクトであり、datetimeオブジェクトと加減算することでdatetimeオブジェクトの指し示す日付時刻を更新できます。
プログラム「p3.py」では「アラーム間隔」に1分を指定(minutes=1)しています。分以外にも次のものが指定できます。
| 引数 | 単位 |
| days=0 | 日 |
| seconds=0 | 秒 |
| microseconds=0 | マイクロ秒 |
| milliseconds=0 | ミリ秒(1000マイクロ秒) |
| minutes=0 | 分(60秒) |
| hours=0 | 時(3600秒) |
| weeks=0 | 週(7日) |
0の部分に設定したい値を指定します。datetime.timedelta()関数にはカンマで区切ることで複数の設定値を指定できます。
「初回のアラーム時刻」と「アラーム間隔」は好きな値に変更してください。
4.5. プログラムの実行と検証
作成したアプリケーションの実行にはターミナルを使用します。
ターミナルを起動しcdコマンドでspeechディレクトリの中に移動してください。speechディレクトリの中にはPythonプログラム「p3.py」と音声ファイル「voice.mp3」があるはずです。
以下のコマンドを入力してください。アプリケーションが実行されます。
./p3.py
アプリケーションの実行中は以下のようなメッセージがターミナル上に表示されます。
アラームは「2021-02-02 18:15:00から0:01:00ごと」に設定されました 次のアラームは2021-02-02 18:16:00です 次のアラームは2021-02-02 18:17:00です 次のアラームは2021-02-02 18:18:00です
スピーカーから音声ファイル「voice.mp3」の内容が再生され、「次のアラームは・・・」と「アラームの設定時刻」が更新されれば成功です。
また、「アラーム間隔」に日(days=1)を指定した場合の結果は次の通りです。
アラームは「2021-02-02 18:20:00から1 day, 0:00:00ごと」に設定されました 次のアラームは2021-02-03 18:20:00です
本プログラムは設定された「アラーム間隔」が来るたびに音声ファイルを再生し、「アラームの設定時刻」の更新を繰り返します。
終了するにはキーボードの「Ctrl+c」を押してください。
5. まとめ
「ラズパイで日本語テキストを読み上げる」のパート2ではあらかじめ録音した音声ファイルを再生するPythonプログラムを2つ紹介し、応用例としてタイマーを使ったアラームアプリケーションを作成しました。
コーディングは「PEP8」と呼ばれるコーディング規約を使って行い、Pythonのプログラムをゼロから作成する方法も合わせて説明しました。
パート3、パート4では残る2つの音声ファイルの作成方法を、複数のプログラムを連携してアプリケーションを作成する手順を交えながら紹介します。
今回の連載の流れ
(1)日本語テキストを音声に変換するには?
(2)あらかじめmp3に録音した音声を再生する(今回)
(3)REST(Web API)を使って発話する
(4)OpenJTalkを使ってオフラインで音声合成


