REST(Web API)を使って発話する
(1)日本語テキストを音声に変換するには?
(2)あらかじめmp3に録音した音声を再生する
「ラズパイで日本語テキストを読み上げる」のパート3では、サーバで作成する方法を説明します。
インターネットを介したRESTを使用して音声合成(Text-to-Speech、TTS)サーバと通信し音声ファイルを作成します。使用する音声合成サーバはGoogle gTTSです。
音声ファイルの再生にはパート2で作成したPythonプログラムを使用します。前回のアプリケーションはプログラム一本で完結しましたが、今回はシェルスクリプトを使って2本のプログラムを連携させる汎用性の高い方法を紹介します。

目次
- RESTでテキストをサーバに送り音声ファイルを作成
- コマンドラインから情報を受け取るように前回のPythonプログラムを改修
- 2.1. 本プログラムの構成
- 2.2. Pythonプログラム p4.py
- 2.3. プログラムの説明
- 2.4. プログラムの実行と検証
- Googleの音声合成サーバ「gTTS」を使用する
- 3.1. 本プログラムの構成
- 3.2. 準備
- 3.3. Pythonプログラム p5.py
- 3.4. プログラムの説明
- 3.5. プログラムの実行と検証
- シェルスクリプトを使って音声ファイルの作成と再生を連携
- 4.1. 本シェルスクリプトの構成
- 4.2. シェルスクリプト s1.sh
- 4.3. シェルスクリプトの説明
- 4.4. シェルスクリプトの実行と検証
- まとめ
1. RESTでテキストをサーバに送り音声ファイルを作成
パート3ではRESTで読み上げるテキストをサーバに送り作成した音声ファイルを再生する方法を紹介します。
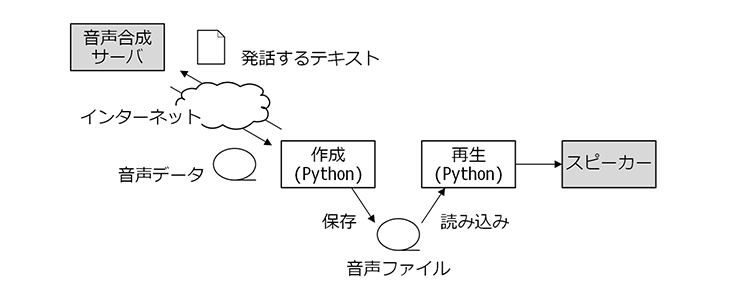
サーバで作成した音声ファイルを再生
サーバへ読み上げるテキストを送信し、作成された音声ファイルを受け取るのにRESTと呼ばれる技術(インターフェース)を使用します。
RESTとは「Representational State Transfer」の略称で、サーバなどの離れた場所にあるコンピュータ上の機能をインターネット経由で使用するための技術です。
RESTによる通信はWebブラウザと同じ仕組みを使うことが規定されているので、シンプルで信頼性の高いデータの送受信が行えます。
Webブラウザと同じ方法で遠隔地にあるサーバの機能を利用する仕組みを「Web API」と呼び、RESTもその一種です。
今回のパート3ではGoogle gTTSを使用します。
Google gTTSはText-to-Speech(音声合成)の機能を提供するサーバで、RESTで読み上げるテキストをサーバに送ると音声に変換されたデータが返却されます。受け取ったデータを音声ファイルとして保存することで一連の処理が終わります。
GoogleからGoogle gTTSを使用するためのPythonライブラリ「gtts」が提供されているので、一連の処理も数行のソースコードで完結します。
RESTで読み上げるテキストをサーバに送り、作成した音声ファイルを再生する方法を使えば、簡単にその場の状況に合ったメッセージを人間の発話に近い音声で読み上げることができます。
ただし
- アプリケーションの実行中は常にインターネットに接続する必要がある
- 完全に無料ではない
という点は大きなデメリットです。
また、インターネット接続ではリアルタイム性や可搬性に不安が生じます。さらにGoogle gTTSでは、月間に無料で使用できる文字数を超過して音声合成を行うと自動的に課金されるので、アプリケーションを設計する際には十分注意してください。
Google gTTSの利用料金はこちらを参照してください。
パート3では
- パート2で作成したプログラム「p2.py」を今回作成するプログラムから利用できるように改修(p4.py)
- 読み上げるテキストをサーバに送り音声ファイルを作成するプログラム「p5.py」をコーディング
- 音声ファイルの作成(p5.py)の再生(p4.py)をシェルスクリプトで実行
の手順で作業を進めます。
「1.」の改修はPythonのプログラム内で直接記載していた「音声ファイルのファイル名」を、コマンドラインから受け取れるようにします。これによって音声ファイルを再生するプログラムが汎用的なコマンドのように利用できます。
「2.」では、リアルタイムでその場の状況に合ったメッセージが音声合成できることを確認するため「現在の日付時刻を含めたテキスト」をサーバに送り音声ファイルを作成します。
2. コマンドラインから情報を受け取るように前回のPythonプログラムを改修
前回作成した「音声ファイルを再生するプログラム(p2.py)」を、動作に必要な情報をコマンドラインから受け取るように改修します。
2.1. 本プログラムの構成
以下がコマンドラインから情報を受け取るように改修したPythonのプログラムの構成です。

システム構成
途中まではパート2で紹介した「タイマーを使ったアラームアプリケーションの作成」と同じです。パート2の『準備(タイマーを追加できるようにp2.pyを改修)』を参照してください
作成するPythonプログラム「p4.py」でmain()関数に加える処理は、再生する音声ファイルの名前をコマンドライン引数から取得するソースコードです。
「コマンドライン引数」とは、ターミナルからコマンド(プログラム)を起動する際にコマンド名の後ろに記述する文字列です。
ffplayコマンドをターミナルから起動する場合は以下のように入力します。(詳細はパート2を参照)
ffplay -nodisp -autoexit -hide_banner voice.mp3
先頭のffplayは起動するコマンド名です。続く「-nodisp -autoexit -hide_banner voice.mp3」は起動した後のffplayに情報として渡されます。
これがコマンドライン引数です。この場合ffplayコマンドはスペースで区切られた-nodisp、-autoexit、-hide_banner、voice.mp3の4つの文字列を外部から受け取ります。
Raspberry Pi OSのベースとなるLinuxではこの文字列を「オプション」と呼ぶ場合もあります。
ここで作成するプログラム「p4.py」も、この機能を使用してプログラムの外部から「再生する音声ファイルの名前」を受け取ります。
例えば、ターミナル上で次のように入力した場合を例に説明します。
./p4.py voice.mp3
このコマンド入力によってp4.pyが起動し、p4.pyはコマンドライン引数の配列を受け取ります。配列はPythonが自動的に作成し「sys.argv」の名称でプログラム中、どこからでも参照できます。
文字列「voice.mp3」もこの配列に格納されていますが注意が必要です。
Pythonが自動的に作成するコマンドライン引数の配列「sys.argv」にオプションだけでなく、先頭の「コマンド部分」も含まれます。
ターミナル上で上記のように入力した場合のコマンドライン引数の配列「sys.argv」は次の通りです。
| 要素番号 | 格納される文字列 |
| 0 | ./p4.py |
| 1 | voice.mp3 |
これによってsys.argv配列の要素数は2となります。
また、sys.argv[0]に格納される文字列は、ターミナル上から入力した通りとなります。
ターミナルから「./p4.py」と入力すればsys.argv[0]は「./p4.py」、「/home/pi/p4.py」と入力すれば「/home/pi/p4.py」となります。
2.2. Pythonプログラム p4.py
以下が外部から再生する音声ファイルの名前を受け取って再生するプログラムです。p4.pyの名前で保存してください。
#!/usr/bin/env python
import sys
import os
import subprocess
def main():
if len(sys.argv) < 2 or sys.argv[1] == "":
return 1
voice_file = sys.argv[1]
code = speech(voice_file)
return code
def speech(voice_file):
if not os.path.exists(voice_file):
return 2
subprocess.call(["ffplay", "-nodisp", "-autoexit", voice_file],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL)
return 0
if __name__ == "__main__":
sys.exit(main())
2.3. プログラムの説明
main()関数に新たに追加したif文
if len(sys.argv) < 2 or sys.argv[1] == “”:
はコマンドライン引数に渡された「音声ファイル名(と思われる文字)」をチェックしています。(ファイルの存在チェックはspeech()関数で行う)
ターミナル上から正しく「コマンド 音声ファイル名」と入力されている場合、sys.argv配列の要素数は2になるので、要素数が2に満たない場合は直ちにプログラムを終了します。(終了ステータス「1」)
if文に含まれる条件「sys.argv[1] == “”」は一見するとあり得ないように思われますが「長さが0の文字列(空文字)」をコマンドライン引数として渡すことは可能です。この条件によって空文字が渡された場合も直ちにプログラムを終了します。
2.4. プログラムの実行と検証
作成したアプリケーションの実行にはターミナルを使用します。
p4.pyと音声ファイル「voice.mp3」があるディレクトリに移動し以下のコマンドを入力してください。
./p4.py voice.mp3
スピーカーから音声ファイル「voice.mp3」の内容が再生されましたか?
音声ファイルの名前を変更し、その名前がコマンドのオプションとして引き渡すことができるかも確認してみましょう。もしp4.pyと音声ファイルが別のディレクトリにある場合は「./p4.py /home/pi/voice.mp3」というようにパスを含めます。
3. Googleの音声合成サーバ「gTTS」を使用する
音声ファイルを再生するプログラム「p4.py」の準備が整ったら、テキストをサーバに送り音声ファイルを作成するプログラム「p5.py」に取りかかります。
3.1. 本プログラムの構成
「p5.py」は、発話するテキストデータをサーバに送り、音声ファイルを作成するプログラムです。p5.pyには再生する機能は含めず、後述するシェルスクリプトでp4.pyと連携して再生させます。

システム構成
発話するテキストは、リアルタイムにその場の状況に合ったメッセージを音声合成できるか確認できるように「現在の日付時刻」を含めます。
以下がプログラムの処理フローです。

サーバで音声ファイルを作成する処理フロー
主処理はmain()関数です。main()関数が呼び出されると(プログラムがスタートすると)最初にコマンドライン引数から作成する音声ファイルの名前を取得します。ここまではp4.pyと同じです。
その後は
- create_message()関数を呼び出しサーバに送るテキストを作成
- create_voice_file()関数を呼び出し、音声ファイルを作成
します。
「1.」のcreate_message()関数の中で現在の日付時刻取得し、
「2021年2月2日、火曜日、10時43分24秒です。」
の形にフォーマットします。
「2.」のcreate_voice_file()関数の中では「1.」で作成したテキストをGoogle gTTSに送り、受け取ったデータから音声ファイルを作成します。音声ファイルの名前はコマンドライン引数から受け取ったファイル名です。一連の処理はGoogleが提供するPythonのライブラリ「gtts」が大部分を行うため非常にシンプルです。
3.2. 準備
Google gTTSにアクセスして音声ファイルを作成するプログラムを作成するにはGoogleが提供するPythonのライブラリ「gtts」をインストールしておきます。
ターミナルを起動して以下のコマンドを入力してください。
pip install gTTS
3.3. Pythonプログラム p5.py
以下が読み上げるテキストをサーバに送り音声ファイルを作成するプログラムです。p5.pyの名前で保存してください。
#!/usr/bin/env python
import sys
import os
import datetime
from gtts import gTTS
def main():
if len(sys.argv) < 2 or sys.argv[1] == "":
return 1
voice_file = sys.argv[1]
message = create_message()
print("読み上げるテキスト: 「" + message + "」")
code = create_voice_file(message, voice_file)
return code
def create_message():
now = datetime.datetime.now()
message = now.strftime("%Y年%-m月%-d日") + "、"
day_of_week = ["月", "火", "水", "木", "金", "土", "日"]
message = message + day_of_week[now.weekday()] + "曜日、"
message = message + now.strftime("%-H時%-M分%-S秒") + "です。"
return message
def create_voice_file(message, voice_file):
if os.path.exists(voice_file):
os.remove(voice_file)
tts = gTTS(text=message, lang="ja")
tts.save(voice_file)
return 0
if __name__ == "__main__":
sys.exit(main())
3.4. プログラムの説明
このプログラムでは現在の日付時刻を含むテキストをサーバに送ります。
現在の日付時刻を取得・フォーマットするための機能を持つのはPythonの標準ライブラリ「datetime」です。このdatetimeライブラリをimport文で読み込みます。
同時にGoogle gTTSにアクセスするためのライブラリ「gtts」も読み込みます。本プログラムではgttsライブラリ内のgTTSオブジェクトのみを使用するので通常のimport文ではなく
from gtts import gTTS
と記述します。
本記事で紹介したPythonプログラムのmain()関数は数字を呼び出し元に返す(戻り値)ようにしています。この数字はシェルスクリプトなどから本プログラムを実行する際に利用され「終了ステータス」と呼ばれます。
終了ステータスでどの数字を返すかはアプリケーションによって自由に決めることができますが、本記事で紹介するPythonのプログラムではRaspberry Pi OSのベースとなるLinuxの慣例に従い、「0は正常終了」「0以外は異常終了」を意味するようにしています。
3.5. プログラムの実行と検証
作成したアプリケーションの実行にはターミナルを使用します。
p5.pyのあるディレクトリに移動し以下のコマンドを入力してください。また音声ファイルの確認にp4.pyを使用するので同じディレクトリ内に配置します。
./p5.py voice.mp3
現在のディレクトリ内に「voice.mp3」が作成されたはずです。
p5.py内では音声ファイルを作成する直前に同名のファイルを削除するので、ファイルの更新日時からも音声ファイルが作成されたことがわかります。
作成されていない場合はインターネットに接続できないことが考えられます。
作成された音声ファイルを再生するにはターミナル上で次のように入力します。
./p4.py voice.mp3
音声ファイルが再生されたはずです。
音声ファイルにp5.pyを起動した時点の日付時刻を元にした
「2021年2月2日、火曜日、10時43分24秒です。」
といった音声が記録されていれば成功です。
日付時刻が大きくずれている場合はラズパイの時間を調整してください。
続いてシェルスクリプトを使って音声ファイルの作成(p5.py)と再生(p4.py)を連携します。
4. シェルスクリプトを使って音声ファイルの作成と再生を連携
シェルスクリプトを使って作成したプログラムを連携する方法を紹介します。
4.1. 本シェルスクリプトの構成
以下が音声ファイルの作成(p5.py)と再生(p4.py)を連携するシェルスクリプトの構成です。
システム構成
4.2. シェルスクリプト s1.sh
以下が、作成したPythonのプログラムを連携するシェルスクリプトです。s1.shの名前で保存してください。
#!/bin/bash
# 音声ファイルの名前を指定
VOICE_FILE="voice.mp3"
# 古い音声ファイルが残っている?
if [ -f $VOICE_FILE ]; then
# 古い音声ファイルを削除
rm $VOICE_FILE
fi
# 音声ファイルを作成
./p5.py $VOICE_FILE
CODE=$?
if [ $CODE -ne 0 ]; then
# 音声ファイル作成に失敗 -> エラーメッセージ
echo 音声ファイルの作成に失敗 code=$CODE
exit
fi
# 音声ファイル作成に成功 -> 再生
./p4.py $VOICE_FILE
4.3. シェルスクリプトの説明
最初に音声ファイルの名前を決め、変数「VOICE_FILE」に格納しておきます。
音声ファイルが存在している場合は削除します。その後は作成(p5.py)、再生(p4.py)の順でPythonプログラム起動します。
if文を使い音声ファイルが作成されなかった場合にはエラーメッセージを表示して処理を打ち切るようにします。
シェルスクリプトに馴染みのない方も多いと思われるので各行にコメントを記載しました。
シェルスクリプトの基本は「ターミナル上に順次入力していくコマンド」を列挙したものです。加えて条件判定や繰り返しなどの制御構文や変数も使用できます。
シェルスクリプトの詳細は次回以降、随時解説していきます。
4.4. シェルスクリプトの実行と検証
作成したアプリケーションの実行にはターミナルを使用します。
s1.sh、p5.py、p4.pyのあるディレクトリに移動し以下のコマンドを入力してください。
./s1.sh
音声ファイル「voice.mp3」が新たに作成された後(既に存在していた場合はファイルの更新日時が現在の日付時刻に変わる)に再生されたはずです。
5. まとめ
パート3ではWeb APIの一つであるRESTのインターフェースを使って、発話するテキストをサーバに送り音声ファイルを作成する方法を紹介しました。
この方法は設定の手軽さ、取り扱いのしやすさ、音声のクオリティなどバランスに優れている方法です。ただしインターネット接続が必要なのでリアルタイム性や可搬性に不安が残ります。同様のサービスはいくつかありますが、今回のGoogle gTTSのように完全な無料ではないケースもあり利用には注意が必要です。
また本記事では、プログラムを音声ファイルの「作成」と「再生」のパートに分け、シェルスクリプトを使って両者を連携する方法を紹介しました。Raspberry Pi OSのベースとなっているLinuxでは、こういった連携によってアプリケーションを構築していく方法がよく採用されます。本記事では今後もこの方法で解説を進めます。
次回のパート4では、インターネット接続を必要としない音声ファイルの作成方法を紹介します。
今回の連載の流れ
(1)日本語テキストを音声に変換するには?
(2)あらかじめmp3に録音した音声を再生する
(3)REST(Web API)を使って発話する(今回)
(4)OpenJTalkを使ってオフラインで音声合成


