撮った画像を読み上げる、おしゃべりカメラにしよう
第1回:初めの一歩、ラズパイに目、耳、口を追加する
第2回:ボタンとウェブサーバー機能を付けて、カメラ、マイクを操作
第3回:NTT docomoのAPIを使って、画像認識カメラを作る
こんにちは、ヨシケンです!
前回記事では、写真に写っている料理や風景などを、画像APIにより解析するようにしました。だんだんスマートなカメラになってきたのではないかと思います。
今回はもう一歩進めて、スピーカーを使ってこのデバイスに口を付け、画像解析した結果をしゃべってくれる面白いカメラにして行きたいと思います。

音声合成APIを使って、様々な声でカメラをしゃべらせる
前回に引き続き、docomo APIの中から音声合成APIを使って、テキストを発話させます。
男女、及び動物風な声まであらかじめ用意されていて、このAPIを使うだけで様々な声を出すデバイスを作ることができます。
音声合成APIが使用できるように、Docomo Developer Supportページから、機能を追加しておいて下さい。
今回の記事で必要な物一覧
上記が入るような箱(ここでは100均で売っている紙製お弁当箱のようなものを使いました)
今回の記事の流れ
1.ボタンを押して画像解析を行う
2.音声合成APIを導入して、発話機能を追加
3.カメラケースを作って、撮影、読み上げをまとめて行う
4.まとめ
1.デバイスのボタンを押して画像解析
それではまず前回のプログラムに、カメラのシャッターを切るようにボタンを押して、撮った画像を解析するようにします。
紙製の箱の中に、ラズパイ、バッテリー、カメラ、ボタンなどを収納しておきます。

カメラで写真を撮るファンクションとして、camera()を追加しました。写真を保存する時、フォルダ名を日付、ファイル名を撮った時間で作成しています。
ボタンを押すのを待ち受ける部分は、第2回の記事と同様の仕組みです。
背景に水色が付いている部分が、前回のプログラムから追加する部分です。
このプログラムを流して、ボタンを一回押すと写真撮影、画像解析ができる事を確かめておいて下さい。
ちなみにパイ・カメラで写真を撮るとき、日付別のファイルを作っているので管理者権限のsudo pythonで流してくださいね。
また、modelパラメータに何も指定しない場合、解析カテゴリを一つづつ順に適用してくれるようにしています。


ちょっとピンボケですが、ちゃんと“ホワイト系”の“ゆで卵”と識別してくれました。その他の項目も拾ってしまったのは、ご愛敬ですね。
2.音声合成APIの導入
それでは今度は、この解析結果を読み上げる事ができるようにします。docomo APIには、音声合成の機能もあるので、それを使っていきます。
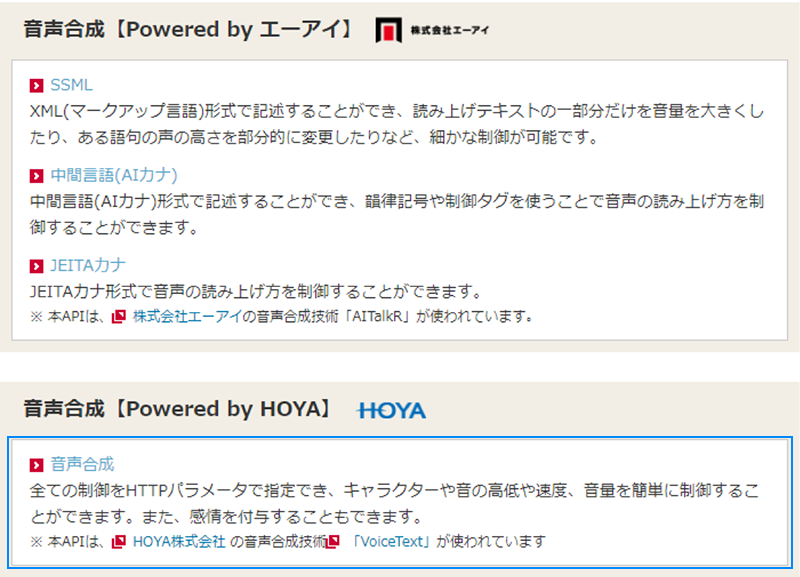
音声合成APIにも幾つかあるのですが、このPowered by HOYAの音声機能は、声の種類を色々選べたり、感情も変えたりする事ができます。
APIの詳細などは、こちらの機能別リファレンスに詳しく載っていますので、適宜参照して下さい。
このAPIのパラメータには以下のようなものがあり、話者や感情、しゃべる速さなどが選べます。今回は一番標準的な速度、感情で、harukaという女性の声を使ってみます。
| キー | 必須 | 説明 | 制限・初期値 |
| text | ○ | 合成するテキスト。エンコーディングは UTF-8。Unicode で 200 文字以内。 | |
| speaker | ○ | 話者名。以下のいずれかを指定します。 show (男性) haruka (女性) hikari (女性) takeru (男性) santa (サンタクロース) bear (凶暴なクマ) |
|
| emotion | – | 感情カテゴリの指定。以下のいずれかを指定します。 happiness(喜) anger (怒) sadness(悲) |
話者 haruka、hikari、takeru、santa、bear にのみ使用できます。 |
| emotion_level | – | 感情レベルの指定。1または2を指定できます。数値が大きいほど感情が強くなります。 | 初期値:1 |
| pitch | – | 音の高低を数値で指定します。値が小さいほど低い音になります。 | 初期値:100(%), 範囲:50(%)から200(%) |
| speed | – | 話す速度を数値で指定します。値が小さいほど遅い話し方になります。 | 初期値:100(%), 範囲:50(%)から400(%) |
| volume | – | 音量を数値で指定します。値が小さいほど小さい音になります。 | 初期値:100(%), 範囲:50(%)から200(%) |
| format | – | 音声ファイルフォーマット。以下のいずれかを指定します。 wav(圧縮なし) ogg(Ogg Vorbisフォーマットでの圧縮) |
初期値:wav |
では前段のPythonプログラムに、この音声APIを追加していきます。
まず、合成音声APIのURLに、以下をセットします。
次にspeech()というファンクションを作って、音声APIにヘッダー、パラメータを指定します。
そして、画像から取得したobject情報を、messageとして音声APIに渡します。
message += objects.encode(‘utf-8’) + “が写っているかもしれません!”code, data = speech(message, speaker, VOLUME)
合成音声APIにより音声ファイル(speech.wav)が作られ、これをaplayコマンドにより、スピーカーから出力します。スピーカーには、以前調べたDEVICE番号、CARD番号を指定します。
これらの仕組みを、これまでのプログラムに追加して、button_cat_speech_camera.pyとしました。
こちらにzipファイルとして保存していますので、解凍して参照してみて下さい。
3.カメラケースを作って、撮影、読み上げをまとめて行う
それではやっと工作っぽいところまで来て、カメラのような外観を作っていきます。ラズパイやカメラ、ボタンなどがまとめて入るカメラケースを作ります。
ここでは、100均で売っている紙の入れ物を使って、カッターで穴を開けて、作っています。ラズパイ、カメラの形に合わせて、それが通る穴をカッターで開けて下さいね。
前面(写真左側)に、ペンでカメラっぽい装飾を施すと、より雰囲気が出てきます。

パイ・カメラを、裏側から穴にはめて、留めます。ラズパイ、バッテリーなども箱に入れ、ボタンは外に出るように伸ばします。

最後に、音声ジャックを差す穴を開けて、そこに上からスピーカーをセットして、AIカメラの完成です!

使い勝手を考えて、シャッターを切るボタンの位置や、ラズパイの電源が入りやすいように工夫して下さいね。
それでは、ラズパイの電源、スピーカーをオンにして、カメラとして全ての機能を通しで使ってみましょう。

さきほどの音声API機能付きのプログラムを流して、ボタンを押して写真を撮ってみましょう。
まず手近にあったこんな食べ物を撮ってみました。

そうすると、まず「食事・料理」シーンというのを判別してくれて、ちゃんと「中華まん」というのが分かってくれました。トレイが黒いのでブラック系は分かりますが、他のメッセージはちょっと不思議ですね。
そして、harukaちゃんの声で、「中華まん、が写っているかもしれません」としゃべってくれました!
その際の動画はこちらです。音を出して再生してもらえると、音声合成APIの発話がクリアなのが分かってくれると思います。
次にこんなものも撮ってみました。

こちらもちゃんと「無地、ホワイト系、食パンが写っているかもしれません!」と発話してくれました。

結構かわいい声で読み上げてくれて、ちょっと愛着が湧いてきましたね!
カメラで手近なものの写真を撮って、喋らせてみて下さい。またプログラム中のパラメータを変えると、他の声や感情にする事もできますので、色々試してみて下さい。
4.まとめ
今回は、ボタンを押すことで、写真撮影、画像解析するようにしました。
また音声合成APIを追加して、ラズパイから喋る事もできるようになりました。
紙製ですがカメラ風なケースも作り、シャッターを切って画像解析プログラムを動かすという一連の動作ができるようになりました。
撮った写真を解析して、写った情景や料理を、人間のような声で発話してくれます。かなり未来のカメラのようになってきましたね!
最終的なプログラムはこちら[button_cat_speech_camera.py]にあります(前出のものと同じです)。適宜参照して下さいね。
次回は、もっと多くの物や文字なども読み取る事ができる機能も付けて、よりAIなカメラにしていきたいと思います。
それでは、お楽しみに!
今回の連載の流れ
第1回:初めの一歩、ラズパイに目、耳、口を追加する
第2回:ボタンとウェブサーバー機能を付けて、カメラ、マイクを操作
第3回:NTT docomoのAPIを使って、画像認識カメラを作る
第4回:撮った画像を読み上げる、おしゃべりカメラにしよう(今回)
第5回:顔や文字などを読み取って、自動でメールする
第6回:人の話を聞いて、写真撮影、画像解析するAIカメラを完成させる!






