M5StickVの機械学習で自分だけのモデルをつくる
第1回:M5Stackとカメラを使ってできること、必要なもの
第2回:M5StickVカメラとM5StickCをセットアップして写真を撮る
こんにちは、ヨシケンです!
今回の連載では、M5Stickとカメラをつなげて、AI機械学習からそこに映っている人を自動判別できる機能を搭載したカメラを作っていきたいと思います。第3回となる今回は、M5StickVカメラで撮った写真を使って機械学習させ、エッジAIできるようにしたいと思います。
なお、今回の連載では「M5StickC」を使用していますが、2022年10月現在は売り止めとなっているようで、後継機の「M5StickC Plus」になるため、概要欄にはそちらを紹介させて頂きます。
M5StickC Plusは、M5StickCの後継機で、従来のものより液晶画面が18.7%拡大し、画面解像度も高解像度のものになっています。また、内蔵バッテリが95mAhから120mAhに増量されているなど細かい仕様の変更がありますが、基本的なプログラムの記述や書き込み方法などは従来品と変更ありません。

-

- [ M5StickVカメラでAI機械学習 ]
今回の記事の流れ
このデバイスをつくるのに必要なもの:
| 名前、説明 | デバイス |
|---|---|
| M5StickC Plus ESP32を搭載したArduino互換機。ディスプレイ、BLE、Wifiおよびモーションセンサなどが始めから入っている。 |
 |
| M5StickV カメラとAI機械学習が可能なチップをセットにしたデバイス(ESP32は内蔵しない) |
 |
| マイクロSDカード | 使用可能かどうかをこちらのサイトを参考に確認 |
| GROVEケーブル、USB Type-Cケーブルなど | 必要に応じて適宜。 |
1. M5StickV公式サイトで画像機械学習
M5StickVで写真が撮影でき、前回のサンプル・プログラムで顔の検出までできました。次は自分独自のデータを使って、AIで画像検出をしてみたいと思います。
最終的にはインターホンに写った画像から、そこに写っているのが家族かそうでないかを判別するのが目的です。
自分独自の画像判別ができるように機械学習を一歩ずつやっていきましょう。まず画像の機械学習について基本のプログラムを、こちらのM5StickVの公式サイトからダウンロードします。
https://docs.m5stack.com/en/related_documents/v-training
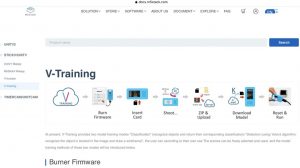
このページ中の「Click here download boot-M5StickV」に、画像を撮影して学習させるためのトレーニング・プログラムがあります。このトレーニング・プログラムをダウンロードしてください。
https://m5stack.oss-cn-shenzhen.aliyuncs.com/resource/docs/VTraining-Client-VerA02B01.zip
ダウンロードしたファイルを解凍すると、以下のような3つのファイルが入っているので、マイクロSDカードを用意して、その直下に保存します。M5StickVで使用できるマイクロSDカードには相性があるようなので、こちらの有志で調べている使用可能なSDカードを探してください。
[ SDカード直下に以下のファイルを保存 ]
|
boot.py kacha.wav startup.jpg |
保存したSDカードをM5StickVに差し込んで、起動します。写真のような初期画面が立ち上がれば、正常にトレーニング・プログラムが読み込まれています。

このプログラムを使って、画像のトレーニング・モデルを作っていきます。分類できる画像の種類(クラス)は10クラスまで登録でき、SDスロットと反対側のボタン(写真の向きで上側)を押すと、クラスを切り替えることが可能です。まずは一つ目のクラスClass:01で写真を撮っていきます。
これで正面にあるAボタンを押して写真を撮るのですが、1クラス当たり35枚以上記録する方が良いようです。M5StickVが使用される状況となるべく同じ環境(光や位置など)で、他のものが写り込まないように、各クラス35枚以上撮りましょう。
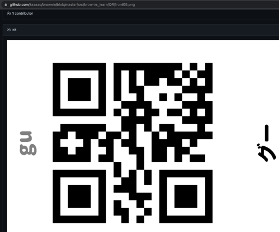
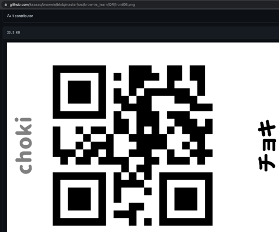
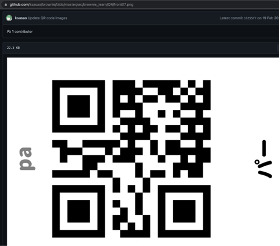
まずテストとして、じゃんけんの手、グー、チョキ、パーを登録しようと思います。各クラスは以下のようになります。
- Class 1:グー
- Class 2:チョキ
- Class 3:パー
写真撮影は、対象の物体の背景をなるべくシンプルに、その物体のみを写すようにしてください。それぞれ35枚以上写真を撮ります。この写真ではバックが黒の状態で、パーの手を撮っています。

写真撮影を行った後にマイクロSDカードの中を見ると、以下のようにフォルダとファイルが保存されていました。
写真が用意できたら、それをV~trainingという機械学習用のサイトにアップロードして学習させます。
http://v-training.m5stack.com/
先ほどのマイクロSD上のtrainとvalidのふたつのフォルダを、ひとつのZIPファイルにして、このサイトにアップロード。Emailのところには結果を送って欲しいメールアドレスを記述します。Click here to upload fileからZIPファイルをアップロードします。メールアドレスを間違えないようにしてください。
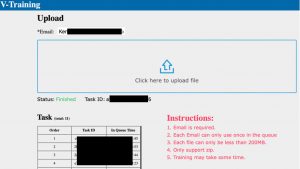
しばらく経つと入力したメールアドレスに結果が返ってきます。返ってきたメールのリンクから、ZIPファイルをダウンロードしてください。ZIP中のモデルを、再度M5StickVのSDカードに書き込みます。
これらの流れがM5Stack社の公式なAI機械学習なのですが、執筆している2022年10月現在、このサイトに画像ファイルをアップロードして数週間経っても返信が来ない状況になっています。時々このような遅延があるようで、公式コミュニティサイトにリクエストを上げていますが、11月時点でも動きがないようです。
ということで、今回はこの公式の機械学習サイトを使わずに別のやり方で自分自身のモデルを作ろうと思います。
2. M5Stack公式以外での機械学習
公式サイト(http://v-training.m5stack.com/)が稼働していないようなので、M5StickVの画像モデルをつくるために、これまで似たような仕組みを作ってくれていた環境をお借りすることにします。
- Google Colaboratory: IAMASの @kotobuki さんが公開しているGoogle ColaboratoryのNotebookを使って、自分で撮った写真を機械学習させるもの
- Brownie; @ksasao さんがMakerFiareなどで公開してくれているM5StickVの画像判別、学習プログラム
ここでは手軽にモデルが作れるBrownieを使わせてもらいます。
Brownieは、@ksasao さんが作ったM5StickVで画像判別ができる仕組みで、その中でもBrownie learnはとても簡単に機械学習をおこなうことができます。詳しくはこちらのサイトを確認してください。
まずBrownieのGithubに行って、プログラム一式をダウンロードします。
https://github.com/ksasao/brownie/tree/master/src/brownie_learn/M5StickV
M5StickVというフォルダ以下にあるファイルを、マイクロSDカードの直下にコピーして、M5StickVを立ち上げます。そうするとBrownieという起動画面が表示され、カメラが映り始めます。

ここでQRフォルダにある、グー、チョキ、パーのQRコードひとつずつM5StickVに読み込ませます。QRコードを読み取ると、「カメラを向けてください」と音声が流れるので、それに合ったグーかチョキかパーの手をM5StickVに向けてください。画面上に赤枠で物体を認識させている状態が続いた後、「データが登録されました」というメッセージが出れば、画像の取得が完了します。
| グー | チョキ | パー |
|---|---|---|
 |
 |
 |
 |
 |
 |
これだけで、画像を機械学習してくれる上に、物体をM5StickVにかざすとそれを見分けてくれます。

M5StickVの画面上に写すだけで、例えばこの写真のようにパーの手をかざして読み取れると、画面枠が緑に光って「パーです!」と音声で教えてくれます。同様にグーやチョキでもやってみてください。結構いい精度で読み取ってくれているので、こちらのビデオの音でも確かめてみてください。
3. モニタの映像を機械学習させる
それでは元々の目的であった、モニタに映った画像を判別する写真を学習させます。我が家にある標準的なインターフォンのモニタに映った画像を使いたいと思います。


ここでは、以下2つのクラスを作成します。
1:家族が写っているもの > Okaeri > 「おかえりなさい!」と話す
2:家族以外の来訪者(配達員を想定)> Haitatsu > 「配達なら置き配してください!」と話す
まず家族のOkaeri写真を撮ります。次にQRer(https://shinoharata.github.io/QRer/)というサイトを使って、QRコードを生成。このサイトにアクセスし、下のボックスに’okaeri’と入力して、Generateを押します。ここで出てきたQRコードをM5StickVに読み込ませてください。
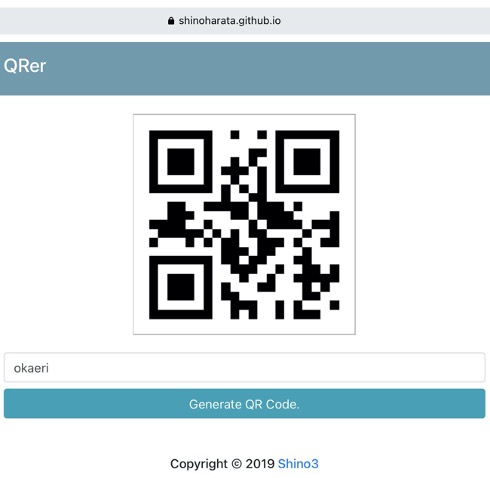

その後、モニタの前に立った家族の画像をM5StickVで読み込ませます。これで画面枠が赤く光って「データが登録されました」と出たら、このokaeriで画像が学習されたことになります。
同様に、haitatsuというQRコードも作成して、M5StickVからモニタに映った配達員の画像を記録しましょう(ここでは帽子をかぶった男の人として撮影しています)。
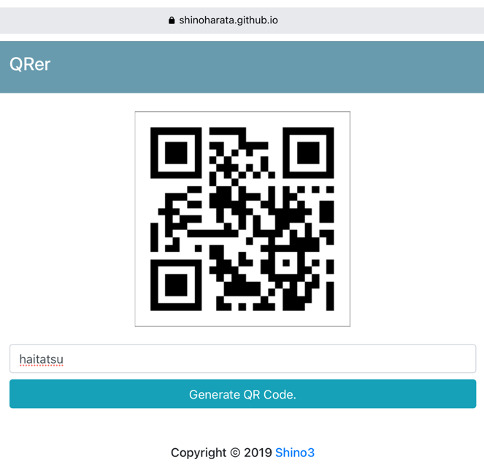

さらに、これらのモデルに応じた音声も用意しておくと、その内容をしゃべってくれます。モデルと同じ名前で、音声ファイルを.wav形式で作成します。以下のような音声を二つのファイルで作りました。このファイルをSDカードの中のvoiceというフォルダの下に置いておきます。
okaeri.wav: 「おかえり!今いくね」
haitatsu.wav: 「配達ならそこに置き配お願いします。」
これでモデルの準備ができました。実際モニタの前に立って、それぞれ見分けられたか確かめてみて下さい。
4. まとめ
今回はM5StickVで撮った写真から、機械学習をおこない、自分独自の判別モデルを作りました。通常ならM5Stackが提供する学習モデルを作りたかったのですが、今回はBrownieを使わせてもらいました。1枚の写真で簡単に機械、転移学習ができて、画像判別することができます。実際読み取る時と同じ環境、背景で撮影するのがポイントのようです。
次回は、今までの写真撮影やM5StickCとの連携、他の機器との連携も加えていきます。

また、それらをまとめて、インターフォン見守りデバイスを完成させます。
お楽しみに!
今回の連載の流れ
第1回: M5Stackとカメラを使ってできること、必要なもの
第2回: M5StickVカメラとM5StickCをセットアップして写真を撮る
第3回: M5StickVカメラでAI機械学習(今回)
第4回: カメラとM5StickCを連動させて、インターネットにも接続して完成!






